
RT-2论文精读
Published:
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
论文重点总结
核心思想与贡献
RT-2的核心贡献是提出了一种视觉-语言-动作 (VLA) 模型,它通过一种简单而强大的方法,将预训练的视觉语言模型 (VLM) 的知识直接用于端到端的机器人底层控制。
- 动作即文本 (Actions as Text): 论文最关键的创新是将机器人的连续动作(如末端执行器位移)离散化,并表示为文本标记 (text tokens)。这使得机器人动作可以和自然语言一样,被VLM直接处理和生成。
- 知识迁移与涌现能力 (Knowledge Transfer & Emergent Abilities): 通过在海量网络数据和机器人轨迹数据上进行“协同微调”(co-fine-tuning),RT-2 不仅学会了机器人技能,还继承了VLM的语义理解、推理和泛化能力。这使得机器人能够执行训练数据中从未见过的、需要语义和逻辑推理的任务(例如,将物品放到特定图标上,或拿起“临时锤子”)。
- 端到端控制 (End-to-End Control): 与之前将LLM用作高级规划器的方法不同,RT-2直接输出底层的机器人动作指令,实现了从像素到动作 (pixels-to-action) 的端到端控制,同时享受大规模预训练的红利。
- 性能验证: 在超过6000次的真实机器人实验中,RT-2在对新物体、新场景的泛化能力上,相比RT-1等基线模型实现了约2倍的性能提升,并展示了符号理解、关系推理和多步规划等多种涌现能力。
论文全文翻译
Abstract
我们研究如何将基于互联网规模数据训练的视觉语言模型直接整合到端到端(end to end)的机器人控制中,以提升泛化能力并实现涌现式语义推理。我们的目标是使单个端到端训练的模型既能学会将机器人观测映射到动作,又能享受来自网络语言和视觉语言数据的大规模预训练带来的好处。为此,我们提出在机器人轨迹数据和互联网规模的视觉语言任务(如视觉问答)上对SOTA视觉语言模型进行协同微调(co-fine-tune)。与其他方法不同,我们提出了一种简单通用的方法来实现这一目标:为了将自然语言响应和机器人动作统一到同一格式,我们将动作表示为文本标记,并像自然语言标记一样直接将其整合到模型的训练集中。我们将这类模型称为视觉语言动作模型(VLA),并实例化了一个此类模型的示例,我们称之为 RT-2。 我们的广泛评估(6k 评估试验)表明,我们的方法能够生成性能优异的机器人策略,并使 RT-2 从互联网规模的训练中获得一系列涌现能力。这包括显著提升对新型物体的泛化能力、能够解释机器人训练数据中未包含的指令(例如将物体放置在特定的数字或图标上),以及能够根据用户指令进行初步推理(例如拿起最小或最大的物体,或距离另一物体最近的物体)。我们进一步证明,引入思维链推理使 RT-2 能够执行多阶段语义推理,例如确定要拿起哪个物体作为临时的锤子(一块石头),或为过于困倦的人选择最适合的饮料(能量饮料)。
1. Introduction
在广泛的 Web 规模数据集上预先训练的高容量模型为下游任务提供了有效而强大的平台:大型语言模型不仅可以实现连贯的文本生成(Anil 等人,2023;Brohan 等人,2022;OpenAI,2023),还可以产生新兴问题解决(Cobbe 等人,2021;Lewkowycz 等人,2022;Polu 等人,2022)以及散文(Brown 等人,2020;OpenAI,2023)和代码(Chen 等人,2021)的创造性生成,而视觉语言模型则可以进行开放词汇的视觉识别(Kirillov 等人,2023;Minderer 等人,2022;Radford 等人,2021),甚至可以对图像中的对象代理交互做出复杂的推断(Alayrac 等人,2022;Chen 等人,2023a,b;Driess 等人,2023;Hao 等人,2022;Huang 等人,2023;Wang 等人,2022)。这种语义推理、问题解决和视觉解释能力对于必须在现实世界环境中执行各种任务的一般性机器人来说非常有用。然而,目前尚不清楚机器人应该如何获得这些能力。虽然暴力方法可能涉及收集数百万个机器人的交互试验,但最强大的语言和视觉语言模型是在来自网络的数十亿标记和图像上进行训练的(Alayrac等人,2022;Chen等人,2023a,b;黄等人,2023)——这一数量不太可能在不久的将来与机器人数据相匹配。另一方面,直接将此类模型应用于机器人任务也很困难:这类模型推理语义、标签和文本提示,而机器人需要基于地面的低级动作,如笛卡尔末端执行器命令。尽管最近有一些工作试图将语言模型 (LLMs) 和视觉语言模型 (VLMs) 集成到机器人中(Ahn 等人,2022;Driess 等人,2023;Vemprala 等人,2023),但这些方法通常只解决机器人规划的“高层”方面,本质上充当一个状态机来解释命令并将其解析为单个原语(例如拾取和放置对象),然后由单独的低级控制器执行,而这些低级控制器本身在训练过程中并不受益于大规模模型丰富的语义知识。因此,在本文中我们提出问题:大型预训练的视觉语言模型能否直接集成到低级别机器人控制中,以提高泛化能力和启用涌现性语义推理?
为此,我们探索了一种既简单又出人意料地有效的方法:直接训练针对开放词汇视觉问答和视觉对话设计的视觉语言模型,使其输出低级机器人动作,同时解决其他大规模的视觉语言任务。尽管这些模型通常被训练以产生自然语言标记,但我们可以使用动作标记化为文本标记并创建“多模态句子”(Driess等人,2023年)来对它们进行训练,从而响应带有相机观察结果的机器人指令,并生成相应的动作。通过这种方式,视觉语言模型可以直接被训练成执行机器人的操作指南。这种方法与之前将视觉语言模型集成到机器人策略中的替代方案(Shridhar等人,2022a)或从头开始设计新的视觉语言行动架构(Reed等人,2022)形成对比:相反,现有的视觉语言模型已经进行了大量的计算投资,没有添加任何新参数就可以进行训练,以输出编码文本的动作。我们将这类模型称为视觉语言行动(VLA)模型。我们在RT-1(Brohan等人,2022)提议的协议的基础上构建了VLA模型,使用类似的语料库,但是将模型扩展到了大型视觉语言主干上。因此,我们称我们的模型为RT-2(机器人变压器2)。请参见图1了解概述。
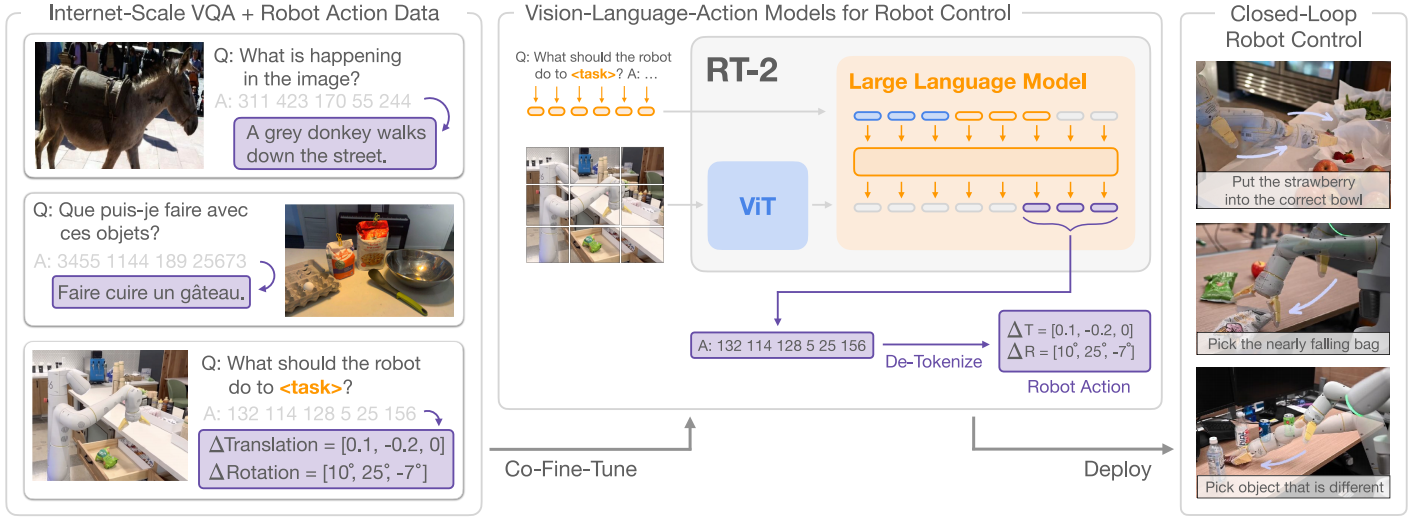 图1 | RT-2概述:我们将机器人动作表示为另一种语言,可以将其转换成文本标记,并与互联网规模的视觉语言数据集一起进行训练。在推理过程中,文本标记被解码成机器人动作,从而实现闭环控制。这使我们能够利用视觉语言模型的主干和预训练来学习机器人的策略,将它们的一些泛化、语义理解和推理转移到机器人控制中。
图1 | RT-2概述:我们将机器人动作表示为另一种语言,可以将其转换成文本标记,并与互联网规模的视觉语言数据集一起进行训练。在推理过程中,文本标记被解码成机器人动作,从而实现闭环控制。这使我们能够利用视觉语言模型的主干和预训练来学习机器人的策略,将它们的一些泛化、语义理解和推理转移到机器人控制中。我们观察到,从这样的视觉语言模型中推导出的机器人策略表现出了一系列显著的能力,它将从机器人数据中学到的物理运动与从网络数据中学习到的对图像和文本进行解释的能力结合起来。除了预期的显著提高对新物体和语义上多样的指令的泛化能力外,我们还观察到了一些新兴的能力。虽然该模型的物理技能仍局限于在机器人数据中看到的技能分布,但该模型通过利用来自网络的知识来解释图像和语言命令,获得了以新的方式部署这些技能的能力。一些示例亮点如图 2 所示。该模型能够重新利用从机器人数据中学到的抓取和放置技能,将对象放置在语义指示的位置附近,例如特定数字或图标,尽管机器人数据中没有这些线索。该模型还可以推理对象之间的关系,以确定要选择哪个对象以及将其放在哪里,尽管机器人演示中没有提供这种关系。此外,如果我们在命令中添加思维链提示,模型就能够做出更复杂的语义推理,比如找出哪种物体可以当作锤子(石头)使用,或者哪种类型的饮料最适合疲劳的人(能量饮料)
 图2 | RT-2泛化能力示例:RT-2能够对各种需要推理、符号理解和人类识别的真实世界情况进行泛化。
图2 | RT-2泛化能力示例:RT-2能够对各种需要推理、符号理解和人类识别的真实世界情况进行泛化。我们的主要贡献是 RT-2,这是一个从在 Web 规模数据上训练的大型视觉语言模型微调而来的模型族,直接用作通用且语义感知的机器人策略。我们在互联网数据以及之前工作的带指令注释的机器人轨迹(Brohan等人,2022)上训练了高达 550 亿参数的模型。在 6 千次机器人评估中,我们展示了 RT-2 在对象、场景和指令上的泛化能力显著提升,并表现出源自 Web 规模视觉语言预训练的广泛涌现功能。
2. Related Work
视觉语言模型。 视觉语言模型(VLM)有几种类别(Gan等人,2022),也许其中两个最相关: (1)表示学习模型,例如CLIP(Radford等人,2021年),它为两种模式学习了通用嵌入; 和(2)形式为{vision, text}→{text}的视觉语言模型,它们学习接受视觉和语言作为输入并提供自由文本。 这两类都用于对下游应用进行预训练,例如对象分类(Radford等人,2021年),检测(Gu等人,2021年)和分割(Ghiasi等人,2021年)。 在这项工作中,我们关注{vision, text}→{text}的视觉语言模型后者类别(Alayrac等人,2022;Chen等人,2023a,b;Driess等人,2023;Hao等人,2022;Li等人,2023,2019;Lu等人,2019)。 这些模型通常在许多不同的任务上进行训练,例如图像字幕生成、视觉问答(VQA)以及多个数据集上的通用语言任务。 尽管以前的研究对机器人等广泛的问题和设置进行了研究VLMs,但我们的重点是通过赋予它们预测机器人动作的能力来扩展VLMs的功能,从而利用VLM中已经存在的知识来实现新的泛化水平。
机器人学习中的泛化。 开发能够在各种情况下取得广泛成功的人工智能控制器一直是机器人研究的目标(Kaelbling,2020;Smith和Coles,1973)。通过从大量且多样的数据集中学习来实现机器人操作的泛化是一种很有前途的方法(Dasari等人,2019;Levine等人,2018;Pinto和Gupta,2016)。通过这样做,先前的方法已经证明了机器人如何能够对新对象实例进行泛化(Finn和Levine,2017;Levine等人,2018;Mahler等人,2017;Pinto和Gupta,2016;Young等人,2021),到涉及新颖组合的任务对象和技能(Dasari和Gupta,2021;Finn等人,2017;James等人,2018;Jang等人,2021;Yu等人,2018),到新的目标或语言指令(Jang等人,2021;Jiang等人,2022;Liu等人,2022;Mees等人,2022;Nair等人,2022a;Pong等人,2022b),到新的语义对象类别(Shridhar et al.,2021;Stone et al.,2023)、未见过的环境(Cui et al.,2022;Du et al.,2023a;Hansen et al.,2020)以及物理特性。与这些先前的工作不同,我们的目标是开发并研究一种可以在所有这些轴上泛化到未见过条件的单一模型。我们方法的一个关键组成部分是利用预训练模型,这些模型在比机器人看到的数据更广泛的数据上进行了训练。
机器人操作的预训练。 在机器人学习中,预训练有着悠久的历史。大多数工作都侧重于用于初始化机器人相机观察器编码器的预训练视觉表示,这些表示要么通过监督ImageNet分类(Shah和Kumar,2021),数据增强(Kostrikov等人,2020;Laskin等人,2020a,b;Pari等人,2021)或针对机器人控制量身定制的目标(Karamcheti等人,2023;Ma等人,2022;Majumdar等人,2023b;Nair等人,2022b;Xiao等人,2022b)。其他工作的预训练语言模型往往作为指令编码器(Brohan等人,2022;Hill等人,2020;Jang等人,2021;Jiang等人,2022;Lynch和Sermanet,2020;Nair等人,2022a;Shridhar等人,2022b)或者用于高级规划(Ahn等人,2022;Driess等人,2023;Huang等人,2022;Mu等人,2023;Singh等人,2023;Wu等人,2023)。我们专门考虑使用预训练的视觉语言模型(VLMs),而不是预训练的视觉模型或预训练的语言模型,因为它们提供了丰富的、基于世界的知识。先前的研究已经研究了在机器人上使用VLM的问题(Driess等人,2023;Du等人,2023b;Gadre等人,2022;Karamcheti等人,2023;Shah等人,2023;Shridhar等人,2021;Stone等人,2023),并且这部分灵感来自于这项工作。这些前人方法使用VLM来表征视觉状态(Karamcheti等人,2023)、识别物体(Gadre等人,2022;Stone等人,2023)、进行高水平规划(Driess等人,2023)或提供监督或成功检测(Du等人,2023b;Ma等人,2023;Summers等人,2023;Xiao等人,2022a;Zhang等人,2023)。虽然CLIPort(Shridhar等人,2021)和MOO(Stone等人,2023)将预训练的VLM集成到端到端的视觉运动操纵策略中,但两者都将结构引入策略,限制了其适用性。值得注意的是,我们的工作不依赖于受约束的二维动作空间,并且不需要校准相机。此外,一个关键的区别是,与这些工作不同,我们利用生成语言的VLM,而我们形式化的统一输出空间使模型权重可以在语言和动作任务之间完全共享,而不引入仅适用于动作模型层组件。
3. Vision-Language-Action Models
在这一部分,我们介绍了我们的模型族以及使训练 VLM 直接执行闭环机器人控制的设计选择。首先,我们描述了我们的模型的一般架构,以及它们如何从通常用于视觉语言任务的模型中派生出来。然后,我们介绍了对预先在大规模数据上进行预训练的大型 VLM 进行微调以直接输出机器人动作的食谱和挑战,使其成为 VLA 模型。最后,我们描述了如何使这些模型适用于机器人任务,解决模型大小和推理速度方面的挑战,从而实现实时控制。
3.1. Pre-Trained Vision-Language Models
本工作中所依赖的 视觉语言模型(Chen等人,2023a;Driess等人,2023)以一个或多个图像作为输入,并产生一系列标记,通常表示为自然语言文本。 这样的模型可以执行各种视觉解释和推理任务,从推断图像组成到回答有关单个对象及其与其他对象的关系的问题(Alayrac等人,2022;Chen等人,2023a;Driess等人,2023;Huang等人,2023)。 表示执行此类广泛任务所需的知识需要大型模型和大规模的数据集。在这项工作中,我们对先前提出的两个视觉语言模型进行微调,作为视觉语言动作模型:PaLI-X(陈等,2023a)和PaLM-E(Driess 等,2023)。我们将这些模型的视觉语言版本称为RT-2-PaLI-X和RT-2-PaLM-E。我们利用了从数十亿到数万亿参数的各种实例。我们在附录D中提供了这两种模型的详细架构描述。
附录D RT-2 的 VLMs
PaLI-X 模型架构由 Dehghani 等人 (2023) 提出的 ViT-22B 处理图像,它可以接受 n 张图像的序列,导致每张图像有 n×k 个标记,其中 k 是每张图像中的补丁数。然后,通过投影层传递的图像标记被一个具有 32B 参数和 50 层的编码器 - 解码器主干消耗,类似于 Tay 等人 (2023) 的 UL2,它联合处理文本和图像作为嵌入以自回归方式生成输出标记。文本输入通常由任务类型以及任何其他上下文组成(例如,“为标题生成(语言)”对于标题任务或“在(语言)中回答:问题”用于视觉问答任务)。在语言表(表 1)上训练的 PaLI-3B 模型使用较小的 ViT-G/14(Zhai等人,2022 年)(2B 参数)来处理图像,并使用 UL2-3B(Tay 等人,2023 年)作为编码器解码器网络。PaLM-E 模型基于一个仅包含解码器的 LLM,它将机器人数据(如图像和文本)投影到语言标记空间,并输出高级计划等文本。在使用的 PaLM-E-12B 的情况下,用于将图像投射到语言嵌入空间的视觉模型是 Chen 等人 (2023 年) 的 ViT-4B。连续变量与文本输入的串联使 PaLM-E 具有全模态性,可以接受多种传感器模式、对象中心表示、场景表示和对象实体引用等多种输入。
3.2. Robot-Action Fine-tuning
为了使视觉语言模型能够控制机器人,它们必须被训练以输出动作。我们直接解决这个问题,在模型的输出中表示为动作令牌,这些令牌与语言令牌的处理方式相同。我们的动作编码基于 Brohan 等人针对 RT-1 模型提出的离散化方法(2022)。动作空间由机器人的末端执行器的 6-DoF 位置和旋转位移以及机器人抓手的张开程度组成,并且有一个特殊的离散命令来终止这一集,它应该由策略触发以表示成功完成。连续维度(除了离散终止命令之外的所有维度)均匀地划分为 256 个桶。因此,机器人的动作可以使用离散桶的序数表示为 8 个整数。为了使用这些离散化的动作对视觉语言模型进行微调,使其成为视觉语言行动模型,我们需要将来自现有标记化模型的标记与离散动作桶关联起来。这需要保留 256 个标记作为动作标记。选择哪些标记取决于每个 VLM 使用的具体分词,我们稍后将在本节中讨论。
为了为 VLM 微调定义目标,我们将动作向量转换为单个字符串,方法是简单地使用空格字符连接每个维度的动作标记:
`terminate Δpos_x Δpos_y Δpos_z Δrot_x Δrot_y Δrot_z gripper_extension`
这样的目标的一个可能的具体化可以是:“1 128 91 241 5 101 127”。我们在实验中微调的两个 VLM,PaLI-X(陈等人,2023a)和PaLM-E(Driess 等人,2023),使用不同的标记化。对于 PaLI-X,每个小于 1000 的整数都有一个唯一的标记,因此我们只需将动作桶与表示相应整数的标记关联起来。对于不提供这种方便数字表示的 PaLM-E 模型,我们简单地覆盖了最不常用的 256 个标记以表示动作词汇表。值得注意的是,训练 VLM 以用动作标记替换现有标记是一种符号微调形式(Wei 等人,2023 年),在以前的研究中已经证明对 VLM 很有效。我们使用上述动作表示,将我们的机器人数据转换为适合于 VLM 模型微调的形式,在这种形式下,我们的输入包括机器人相机图像和文本任务描述(使用标准视觉问答格式“问:机器人应该采取什么行动来[任务说明]?答:“),而我们的输出以数字串或最不常用的标记串的形式呈现,代表机器人的一个动作。
联合微调。 正如我们在实验中所展示的,训练配方中的一个关键技术细节,可以提高机器人性能,那就是使用原始网络数据与机器人数据一起进行联合微调,而不是仅对机器人数据进行简单微调。我们注意到,联合微调导致更通用的策略,因为在微调期间,策略不仅暴露于机器人动作,还暴露于来自大规模网络数据的抽象视觉概念。在联合微调过程中,我们通过增加机器人数据集上的采样权重来平衡每个训练批次中机器人和网络数据的比例。
输出约束。 为了确保 RT-2 在解码过程中产生有效的操作令牌,我们在模型接收到机器人动作任务时仅采样有效操作令牌来限制其输出词汇表,尽管模型仍然可以对标准视觉语言任务生成完整的自然语言标记。
3.3. Real-Time Inference
现代 VLM 的大小可以达到数十亿到数万亿个参数(陈等人,2023a;Driess 等人,2023)。本工作中训练的最大模型使用了 550 亿个参数。在标准台式机或机器人控制中常用的 GPU 上直接运行这样的模型是不切实际的。据我们所知,我们的模型是迄今为止用于直接闭环机器人控制的最大规模模型,因此需要一套新的解决方案来实现高效的实时推理。我们开发了一种协议,使我们能够在多 TPU 云服务上部署 RT-2 模型,并通过网络查询该服务。借助此解决方案,我们可以实现合适的控制频率,并为多个机器人提供相同的云服务。我们在评估过程中使用的最大模型——包含 550 亿个参数的 RT-2-PaLI-X-55B 模型可以在 1-3 Hz 的频率下运行。。该模型的小版本由 50 亿个参数组成,可以以约 5 Hz 的速率运行。
4. Experiments
我们的实验侧重于 RT-2 的现实世界泛化和新兴能力,并旨在回答以下问题:
- RT-2 在场景任务上的表现如何?更重要的是,它能否泛化到新的物体、背景和环境上?
- 我们是否可以观察和测量 RT-2 的涌现能力?
- 参数数量和其他设计决策如何影响泛化?
- RT-2 能否表现出与视觉语言模型类似的思维链推理?
我们在各种条件下使用大约 6000 条评估轨迹评估我们的方法和几个基线,如以下各节所述。除非另有说明,否则我们使用具有动作空间的动作空间在第 3.2 节中描述的 7 关节移动操纵器进行评估。我们还在项目网站上展示了 RT-2 执行的示例:robotics-transformer2.github.io。我们训练了两个特定的 RT-2 实例,它们利用预训练的 VLM:
- RT-2-PaLI-X 是从 5B 和 55B PaLI-X (Chen et al., 2023a) 构建的
- RT-2-PaLM-E 是从 12B PaLM-E (Driess et al., 2023) 构建的
附录E Training Details
我们在PaLI-X (Chen等人,2023a) 5B & 55B模型、PaLI (Chen等人,2023b) 3B模型和PaLM-E (Driess等人,2023) 12B模型的预训练模型上进行联合微调。对于RT-2-PaLI-X-55B,我们使用学习率为1e-3和批大小为2048,并对模型进行了80k个梯度步骤的联合微调,而对于RT-2-PaLI-X-5B,我们使用相同的学习率和批量大小,并对模型进行了270k个梯度步骤的联合微调。对于RT-2-PaLM-E-12B,我们使用学习率为4e-4和批大小为512来对模型进行1M个梯度步的联合微调。这两个模型都是在下一个标记预测目标下进行训练的,这对应于机器人学习中的行为克隆损失。用于表1中语言表格结果的RT-2-PaLI-3B模型,我们使用了学习率为1e-3和批大小为128,并对模型进行了300k个梯度步骤的联合微调。
基准线。 我们用多个最先进的基准模型来挑战我们方法的不同方面进行比较。所有基准都使用完全相同的机器人数据集。为了与最先进的策略进行比较,我们使用了 RT-1 (Brohan et al., 2022),一个基于 Transformer 的 35M 参数模型。为了与最先进的预训练表示进行比较,我们使用了 VC-1 (Majumdar et al., 2023a) 和 R3M (Nair et al., 2022b),通过训练一个带有 RT-1 后背的策略作为输入。为了与其他使用视觉语言模型的架构进行比较,我们使用了 MOO (Stone et al., 2023),它使用了一个视觉语言模型为语义地图创建一个额外的图像通道,然后将其馈入 RT-1 后背。更多详细信息请参见附录 C。
附录C Baselines
我们用多个先进的基准测试来比较我们的方法,这些基准测试挑战了我们方法的不同方面。 所有的基准都使用完全相同的机器人数据集。
- RT-1: Robotics Transformer 1 Brohan等人,(2022),是一种基于变压器的模型,在发布时在类似的任务套件上取得了最先进的性能。该模型不使用基于视觉语言模型(VLM)的预训练,因此提供了重要的数据点,以证明基于VLM的预训练是否重要。
- VC-1:由 Majumdar 等人 (2023a) 提出的视觉基础模型,使用针对机器人任务专门设计的预训练视觉表示。我们使用了来自 VC-1 ViT-L 模型的预训练表示。由于 VC-1 不包含语言条件,因此我们通过通过 Cer 等人 (2018) 的通用句子编码器单独嵌入语言命令来添加它,以使其能够与我们的方法进行比较。具体来说,我们将从语言编码器中获得的语言嵌入标记连接到由 VC-1 生成的图像标记,并将连接的标记序列馈送到 Ryoo 等人 (2021) 的标记学习器中。然后,标记学习器产生的标记序列被送入一个仅解码器的 RT-1 变压器模型,用于预测机器人动作标记。我们端到端地训练了 VC-1 基线并解冻了 VC-1 权重,在训练过程中,这比冻结 VC-1 权重带来了更好的结果。
- R3M:R3M Nair等人(2022年b)与VC-1类似,因为R3M使用预训练的视觉语言表示来提高策略训练。在这种情况下,作者使用Grauman等人(2022)的人类活动数据集Ego4D来学习政策使用的表示。VC-1和R3M都测试了不同的最先进的表征学习方法,以替代使用VLM。为了从R3M预训练表示中获得条件于语言的策略,我们遵循上述为VC-1描述的过程,除了我们使用R3M ResNet50模型获取图像标记,并在训练期间解冻它。
- MOO:Moo 石头等(2023)是一种以对象为中心的方法,首先使用视觉局部模型(VLM)在原始图像中指定感兴趣的对象。这种像素修改的图像随后通过端到端策略进行训练,以完成一组操作任务。此基线对应于一种情况,即使用视觉局部模型作为单独模块来增强感知,但其表示未用于策略学习。
4.1. RT-2 在任务上表现如何,更重要的是,在新对象、背景和环境中泛化情况如何?
为了评估在分布内的性能以及泛化能力,我们将 RT-2-PaLI-X 和 RT-2-PaLM-E 模型与前几节中列出的四个基线进行比较。对于“已见任务”类别,我们使用了与 RT-1 (Brohan et al., 2022) 相同的一套指令,该评估包括超过 200 个任务:36 个用于拾取对象,35 个用于敲击对象,35 个用于竖直放置物品,48 个用于移动对象,18 个用于打开或关闭各种抽屉,以及 36 个用于从抽屉中取出并放入物品。请注意,这些“分布内”的评估仍然会变化物体位置等因素,例如一天中的时间、机器人位置等,需要技能来泛化到环境中的现实变化。
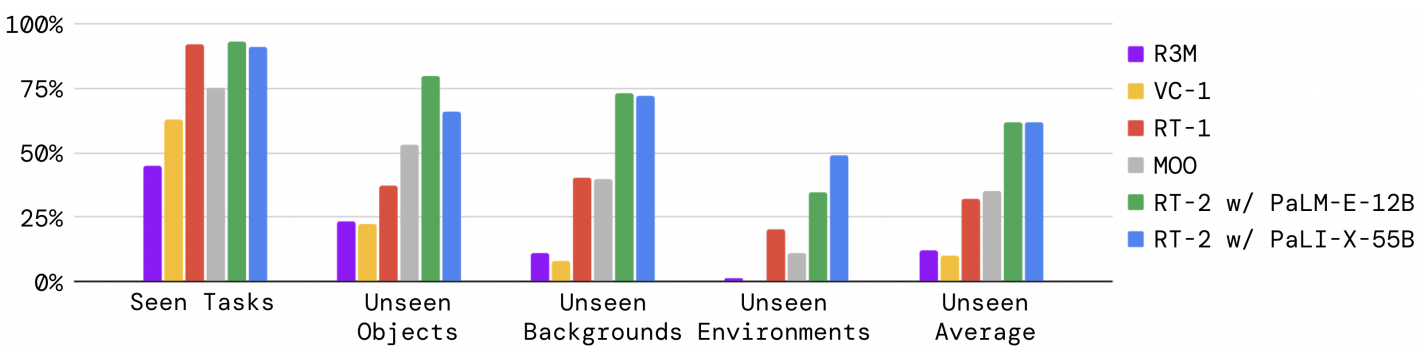
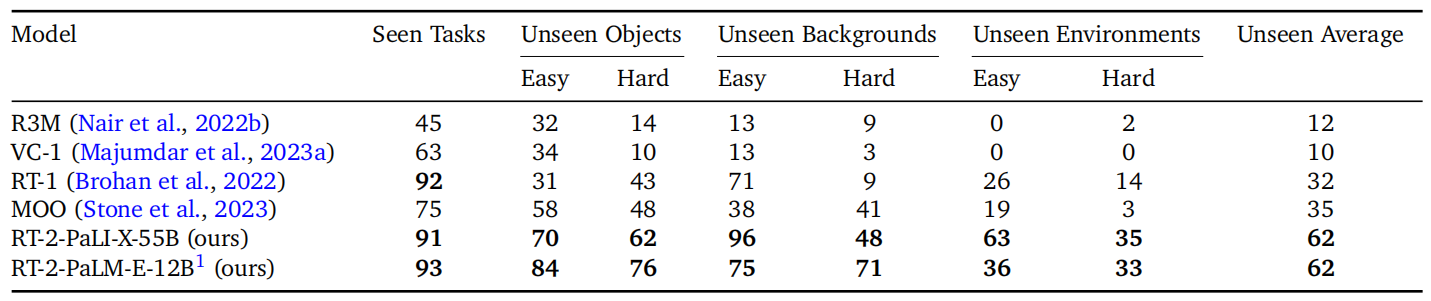
图 3 展示了示例泛化评估,其中分为未见过的类别(对象、背景和环境),并进一步细分为易类和难类。对于未见过的对象,困难案例包括难以掌握和独特的对象(例如玩具)。对于未见过的背景,困难情况包括更多样化的背景和新奇的对象。最后,对于未见过的环境,困难案例对应于具有显示器和附件的视觉上更明显的办公桌环境,而较容易的环境则为水槽。这些评估由超过 280 项任务组成,主要关注许多不同情况下抓取和放置技能。对未见过类别的指令列表在附录 F.2 中指定。

附录F.1 Evaluation Scenarios
为了以定量的方式研究 RT-2 的涌现能力,我们研究了各种具有挑战性的语义评估场景,旨在衡量推理、符号理解以及人类识别等能力。如图 8 所示,展示了这些场景中的一些子集的可视化预览,并在表 3 中显示了用于定量评估的完整指令列表。
附录F.2 Evaluation Instructions
表 2 列出了在对未见过的对象、背景和环境进行模型评估时使用的自然语言指令。每个指令都在 1-5 次之间运行,具体取决于该评估集中的总指令数。表 3 列出了用于评估定量涌现评估的自然语言指令。每个指令都运行了 5 次。
| 任务组 | 任务 |
|---|---|
| 符号理解:符号1 | 将可乐罐移到X附近,将可乐罐移到3附近,将可乐罐移到Y附近 |
| 符号理解:符号2 | 将苹果移到树(图标)旁,将苹果移到鸭子(图标)旁,将苹果移到苹果(图标)旁,将苹果移到匹配的卡片上 |
| 符号理解:符号3 | 把可乐罐放到狗(图标)旁边,把可乐罐推到心形(图标)上方,把可乐罐放到星星(图标)上方 |
| 推理:数学 | 将香蕉移到数字2旁,将香蕉移到二加一的总和附近,将香蕉移到三乘二的答案附近,将香蕉移到最小的数字旁 |
| 推理:商标 | 将杯子移到谷歌(商标)旁,将杯子移到安卓(商标)旁,将杯子移到油管(商标)旁,将杯子移到一个搜索引擎(图标)旁 |
| 推理:营养 | 给我拿一个健康的零食,拿一杯健康的饮料,拿起一杯甜饮料,将健康的零食移到健康的饮料旁,拿起一个咸味零食 |
| 推理:颜色与多语言 | 将苹果移到相同颜色的杯子旁,将苹果移到不同颜色的杯子旁,将绿色薯片移到匹配颜色的杯子旁,将苹果移动到绿色的杯子旁(西语), 将苹果移动到红色的杯子旁(德语), 将苹果移动到绿色的杯子旁(西语), 将绿色薯条移动到红色的杯子旁(法语) |
| 人物识别:名人 | 将可乐罐移到泰勒·斯威夫特(照片)旁,将可乐罐移到汤姆·克鲁斯(照片)旁,将可乐罐移到史努比狗狗(照片)旁 |
| 人物识别:CelebA | 将可乐罐移到戴眼镜的人旁边,将可乐罐移到白发男子旁边,将可乐罐移到黑发女士旁边 |
| 任务组 | 任务 |
|---|---|
| 未见过的物体 (简单) | 拿起香蕉,将香蕉移动到可乐罐附近,将橙色罐子移动到香蕉附近,拿起奥利奥,将奥利奥移动到苹果附近,将红牛罐移动到奥利奥附近,拿起梨,拿起椰子水,将梨移动到椰子水附近,将百事可乐罐移动到梨附近 |
| 未见过的物体 (困难) | 拿起冷萃咖啡罐,拿起大的橙色盘子,拿起咀嚼玩具,拿起大的网球,拿起小鸟装饰品,拿起鱼形玩具,拿起姜味柠檬康普茶,拿起鸡蛋分离器,拿起手表,拿起绿色的雪碧罐,拿起蓝色的超细纤维布,拿起黄色的梨,拿起椒盐脆饼袋,拿起消毒湿巾,拿起菠萝味水,拿起绿色的杯子,拿起腌菜零食,拿起小的蓝色盘子,拿起小的橙色擀面杖,拿起章鱼玩具,拿起猫薄荷玩具 |
| 未见过的背景 (简单) | 拿起绿色的墨西哥胡椒薯片袋,拿起橙色罐子,拿起百事可乐罐,拿起七喜罐,拿起苹果,拿起蓝色的薯片袋,拿起橙子,拿起七喜罐,将橙子移动到水槽附近,拿起可乐罐,拿起海绵,拿起蓝莓味的RXBAR |
| 未见过的背景 (困难) | 拿起手表,拿起鸡蛋分离器,拿起绿色的雪碧罐,拿起蓝色的超细纤维布,拿起黄色的梨,拿起椒盐脆饼袋,拿起消毒湿巾,拿起菠萝味水,拿起绿色的杯子,拿起腌菜零食,拿起小的蓝色盘子,拿起小的橙色擀面杖,拿起章鱼玩具,拿起猫薄荷玩具,拿起瑞典鱼软糖袋,拿起大的绿色擀面杖,拿起黑色的太阳镜 |
| 未见过的环境 (简单) | 拿起可乐罐,拿起苹果,拿起蓝莓味的RXBAR,将苹果移动到可乐罐附近,将蓝莓味的RXBAR移动到苹果附近,将可乐罐移动到蓝莓味的RXBAR附近,拿起蓝色的塑料瓶,拿起海绵,拿起蓝色的薯片袋,将海绵移动到蓝色的塑料瓶附近,将蓝色的薯片袋移动到海绵附近,将蓝色的塑料瓶移动到蓝色的薯片袋附近,将可乐罐移动到白色的马克杯附近,将海绵移动到白色的马克杯附近,将可乐罐移动到黄色的碗附近,将海绵移动到黄色的碗附近,将可乐罐移动到绿色的布附近,将海绵移动到绿色的布附近,将可乐罐移动到盘子附近,将海绵移动到盘子附近,将可乐罐移动到勺子附近,将海绵移动到勺子附近,将可乐罐移动到橙色的杯子附近,将海绵移动到橙色的杯子附近,拿起白色的马克杯,拿起黄色的碗,拿起绿色的布,将白色的马克杯移动到海绵附近,将黄色的碗移动到海绵附近,将绿色的布移动到海绵附近,拿起盘子,拿起勺子,拿起橙色的杯子,将盘子移动到海绵附近,将勺子移动到海绵附近,将橙色的杯子移动到海绵附近,将可乐罐放入水槽,将可乐罐丢入水槽,将可乐罐推入水槽,将海绵放入水槽,将海绵丢入水槽,将海绵推入水槽,将绿色的布放入水槽,将绿色的布丢入水槽,将绿色的布推入水槽 |
| 未见过的环境 (困难) | 拿起可乐罐,拿起苹果,拿起蓝莓味的RXBAR,将苹果移动到可乐罐附近,将蓝莓味的RXBAR移动到苹果附近,将可乐罐移动到蓝莓味的RXBAR附近,将可乐罐移动到订书机附近,将苹果移动到订书机附近,将可乐罐移动到键盘附近,将苹果移动到键盘附近,将可乐罐移动到纸巾盒附近,将苹果移动到纸巾盒附近,将可乐罐移动到纸张附近,将苹果移动到纸张附近,将可乐罐移动到鼠标附近,将苹果移动到鼠标附近,将可乐罐移动到书本附近,将苹果移动到书本附近,拿起记号笔,拿起订书机,拿起鼠标,将记号笔移动到苹果附近,将订书机移动到苹果附近,将鼠标移动到苹果附近,将可乐罐向左推,将可乐罐向右推,将海绵向左推,将海绵向右推,将纸巾盒向左推,将纸巾盒向右推,指向可乐罐,指向海绵,指向纸巾盒 |
如图 4 和附录表 4 所示,RT-2 模型在已知任务上的表现与 RT-1 相似,其他基准线的表现要差一些。在各种泛化实验中,RT-2 模型与基线之间的差异最为明显,这表明视觉语言行动模型的优势在于从其大规模预训练数据中转移出更具一般性的视觉和语义概念。在这里,平均而言,RT-2 的两个版本的表现相似,导致相对于下一个基线 RT-1 和 MOO 约有 2 倍的提升,以及相对于其他基线约有 6 倍的提升。PaLM-E 版本的 RT-2 在更困难的一般化场景下似乎比 RT-2-PaLI-X 表现得更好,但在较容易的场景下表现较差,从而导致类似的整体性能。
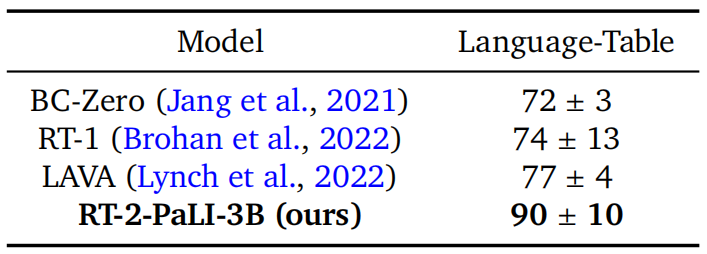
开源语言表格基准。为了提供一个使用开源基线和环境的额外比较点,我们利用了Lynch等人(2022)提供的开源Language-Table模拟环境。我们在几个预测任务上联合微调了一个较小的PaLI 3B模型,包括域内VQA任务,用于Language-Table数据集,并在仿真中评估所得到的策略。对于动作预测任务,我们将动作离散化并编码为文本格式“X Y”,其中X和Y范围从-10到+10,表示末端执行器的二维笛卡尔设定点增量。由于其尺寸减小,生成的模型可以以与其它基线相似的速度(5 Hz)进行推断。本实验的结果如表1所示。我们观察到,在我们的模型与基线相比时,性能显著提升,这表明基于视觉的语言模型预训练加上大型PaLI模型的表达能力可以在其他场景中受益,例如在这个例子中的机器人仿真。我们还在图5中展示了现实世界中样本外行为的质量,演示了新颖的推动任务和以前在这个环境中从未见过的目标物体。

有关Language Table实验的更多详细信息,请参见附录B和D。
附录B 数据集
视觉语言数据集基于陈等人(2023 b)和Driess等人(2023)的数据集混合。这些数据的主要部分由WebLI数据集组成,该数据集包含约100亿对跨模态相似性得分最高的图像文本对,用于训练,共有109种语言。还包括许多其他标注和视觉问答数据集,有关数据集混合的更多信息,请参见Chen等人(2023 b)中的RT-2-PaLI-X和Driess等人(2023)中的RT-2-PaLM-E。在联合微调RT-2-PaLI-X时,我们没有使用陈等人(2023 a)中描述的Episodic WebLI数据集。机器人数据集基于 Brohan 等人(2022)的数据集。它由移动操作机器人收集的演示示例组成。每个演示都附带了来自七项技能之一的自然语言指令:“拾取对象”、“将对象移近物体”、“将对象竖直放置”、“敲倒对象”、“打开抽屉”、“关闭抽屉”、“将对象放入容器中”,以及“从容器中取出对象并将其放在台面上”。更多详细信息,请参见 Brohan 等人(2022)。RT-2-PaLI-X 对机器人数据集进行加权,使其占训练混合物的大约 50% 用于联合微调。RT-2-PaLM-E 在机器人数据集上的权重约为训练混合物的 66%。在表 1 中的“语言表格”部分,我们的模型是在林奇等人。 (2022) 的 Language-Table 数据集上训练的。 我们的模型还针对多个预测任务进行了联合微调:
- 给定两个连续的图像帧和文本指令,预测动作
- 给定图像帧,预测指令
- 给定图像帧,预测机器人臂的位置
- 给定图像帧,预测给定图像帧之间的时间步数
- 给定图像帧和指令,预测任务是否成功
4.2. 我们能否观察并测量RT-2的涌现能力?
除了评估视觉-语言-动作模型的泛化能力之外,我们还希望评估这类模型在多大程度上能够通过从网络上迁移知识,实现超越机器人数据中所展示的新能力。我们称之为涌现性,因为它们通过大规模预训练而出现。我们不期望这种转移能够使新的机器人动作成为可能,但我们确实期望语义和视觉概念、包括关系和名词,在机器人数据中没有看到的情况下也能有效地转移。
定性评估。 首先,我们用我们的 RT-2-PaLI-X 模型来实验,以确定从视觉语言概念中转移的各种涌现能力。我们在图 2 中展示了这种交互的一些示例。我们通过探索发现,RT-2 在场景语境下具有新颖的理解能力和基本推理能力。例如,完成“把草莓放入正确的碗里”的任务需要对不仅仅是草莓和碗是什么有细微的理解,还需要在场景上下文中进行推理,知道草莓应该与相似的水果放在一起。对于“捡起即将掉下的包”的任务,RT-2 表现出物理理解能力,能够区分两个包并识别出置于危险位置的物体。所有这些测试中的相互作用都是机器人数据中从未见过的,这表明了从视觉语言数据到语义知识的迁移。
定量评估。 为了量化这些新兴能力,我们从之前的评估中选择了两个基线模型:RT-1 和 VC-1,并与我们的两个模型进行比较:RT-2-PaLI-X 和 RT-2-PaLM-E。为了减少实验的方差,我们在 A/B 测试框架(Fisher, 1936)下对所有方法进行了评估,在该框架下,四个模型在完全相同的条件下依次进行评估。我们根据推理和语义理解轴将 RT-2 的涌现能力分为三类(每种类别的示例请参见附录中的图 8):
- 符号理解 (Symbolic Understanding): 它明确测试了 RT-2 策略是否从视觉语言预训练中转移出了机器人数据中不存在的语义知识。这一类别的示例指令包括“移动苹果到3”或“把可乐罐推到心上”。
- 推理 (Reasoning): 它展示了底层 VLM 各种推理方面的能力,以控制任务。这些任务需要视觉推理(“将苹果移到与自身颜色相同的杯子上”)、数学(“将X移动到两个加一的总和附近”)和多语言理解(“ mueve la manzana al vaso verde”)。
- 人类识别 (Human Recognition): 包括诸如“将可乐罐移到戴眼镜的人旁边”这样的任务,以证明对人类的理解和识别能力。
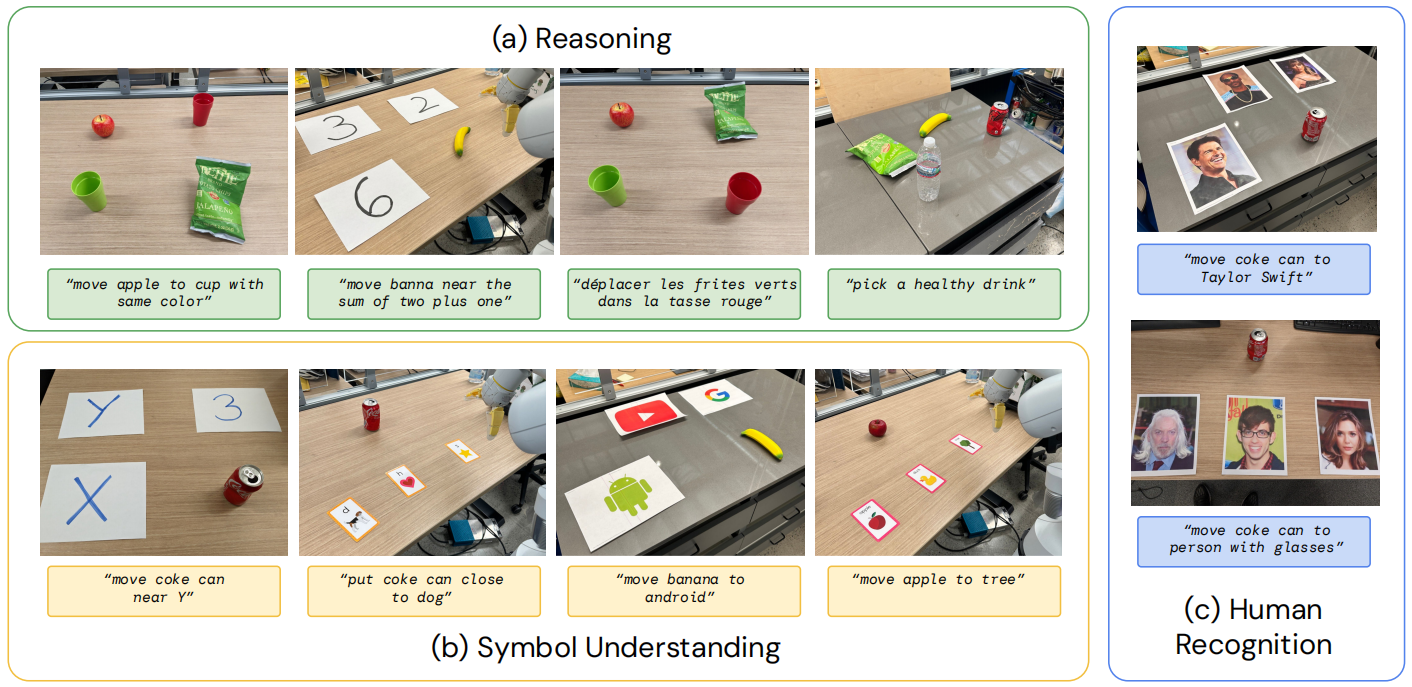
我们在图6(a)中展示了实验结果,所有数值结果在附录H.2中。
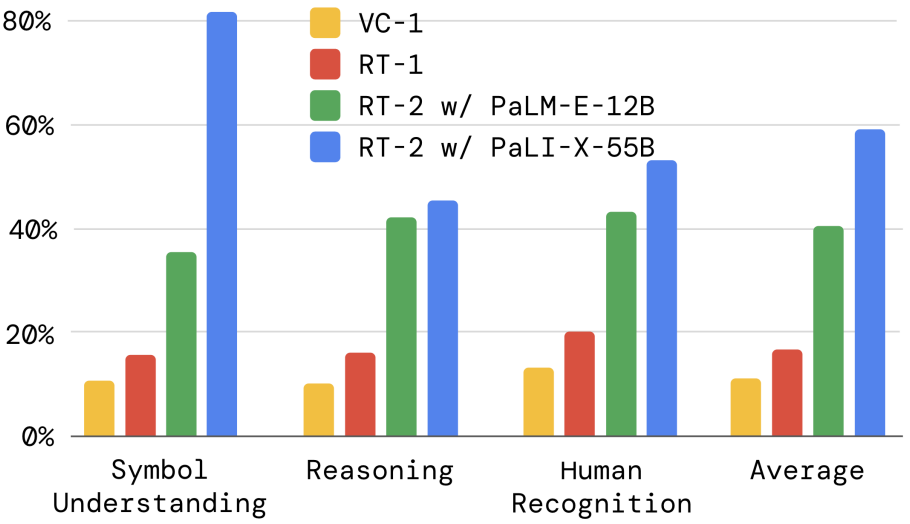
附录H.2. Emergent Evaluation, for Section 4.2
表5列出了我们所有的定量涌现性评估结果。 我们发现,与 RT-1 相比,RT-2 在这些新指令上的性能提高了 2 到 3 倍,而且不需要额外的机器人演示。 这证明了我们的方法如何利用预训练来提高在大规模视觉语言数据集上进行推理的能力。

我们观察到,我们的 VLA 模型在所有类别上都显著优于基线,其中我们的最佳 RT-2-PaLI-X 模型比下一个最佳基线(RT-1)平均成功率高出三倍多。我们还注意到,虽然基于 PaLI-X 的较大模型在平均符号理解、推理和人脸识别方面表现更好,但基于 PaLM-E 的较小模型在涉及数学推理的任务上具有优势。我们将这一有趣的结果归因于 PaLM-E 中使用的预训练混合不同,从而产生了一个在数学计算方面比主要基于视觉预训练的 PaLI-X 更加擅长的模型。
4.3. 参数数量和其他设计决策如何影响泛化?
出于模型大小的灵活性考虑(由于PaLM-E的特性,RT-2-PaLM-E仅限于某些大小的PaLM和ViT模型),我们使用了RT-2-PaLI-X模型进行比较。具体来说,我们比较了两个不同的模型大小:5B和55B,以及三种不同的训练方案:从头开始训练,不使用预训练的VLM权重;只使用机器人动作数据微调预训练模型;以及联合微调(co-training with fine-tuning),这是本工作中主要使用的训练方法,其中我们同时使用原始VLM训练数据和机器人数据对VLM进行微调。因为我们主要关注这些模型的泛化能力,所以我们去掉了这个实验集中的已知任务评估。
在图6b和附录表6中展示了消融实验的结果。
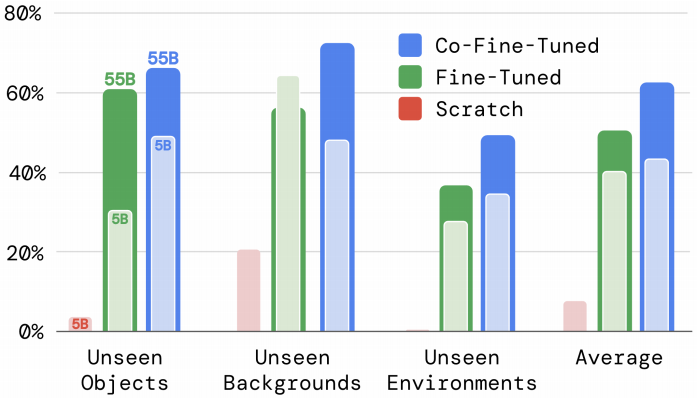
附录H.3. Size and Training Ablations, for Section 4.3
表6详细说明了模型大小和训练方法对消融的影响。我们发现,无论是在哪方面,模型大小都对性能有重要影响,联合微调优于微调,而微调又优于从头开始训练。
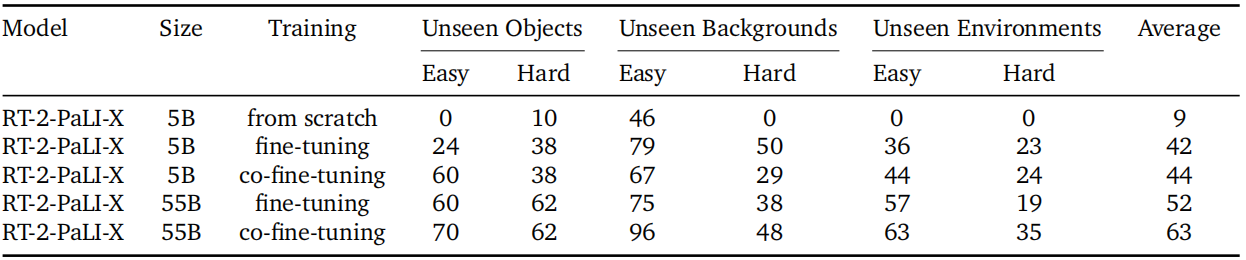
首先,我们观察到从头开始训练一个非常大的模型,即使对于5B模型也会导致性能很差。考虑到这个结果,我们在从头开始训练时决定跳过更大的55B PaLI-X模型的评估。其次,我们注意到联合微调模型(无论其大小如何)比仅使用机器人数据对其进行简单微调能够获得更好的泛化性能。我们认为这是因为保持原始数据在训练中的微调部分周围,使模型不会忘记先前在VLM训练期间学到的概念。最后,不出所料,我们发现模型尺寸的增加会导致更好的泛化性能。
4.4. RT-2 是否可以像视觉语言模型一样展示思维链推理的迹象?
受 LLM 中的思维链提示方法(Wei等人,2022)的启发,我们对带有 PaLM-E 的 RT-2 进行了微调,仅用几百个梯度步骤来提高它共同利用语言和行动的能力,希望这能引发更复杂的推理行为。我们在数据中添加了一个额外的“计划”步骤,首先用自然语言描述机器人即将采取的动作的目的,然后是实际动作标记,例如:“指令:我饿了。计划:拿一包巧克力棒。动作:1 128 124 136 121 158 111255。”这种数据增强方案在视觉推理 (VQA) 数据集和生成操作的数据集之间架起了一座桥梁。
我们定性观察到,采用思维链推理的RT-2能够响应更复杂的指令,这得益于它首先获得了用自然语言规划行动的空间。这一发现为以下观点提供了初步证据:将大型语言模型或视觉语言模型作为规划器(Ahn等人,2022;Driess等人,2023)与底层策略整合到单一视觉语言行动模型中具有可行性。图7和附录I展示了采用思维链推理的RT-2的运行实例。

附录I. Additional Chain-Of-Thought Reasoning Results
我们在图 10 中提供了使用 RT-2-PaLM-E 完成的思维链推理推演的更多示例,如第 4.4 节所述。

5. Limitations
尽管 RT-2 展示了很有前途的一般化特性,但这种方法存在多个局限性。首先,虽然我们证明通过 VLM 进行基于 Web 的预训练可以提高对语义和视觉概念的一般化能力,但机器人不会通过包含这种额外经验来获得执行新动作的能力。模型的物理技能仍然局限于机器人数据中看到的技能分布(见附录G),但它学会了以新的方式部署这些技能。我们认为这是由于数据集在技能轴上不够多样化所致。未来研究的一个令人兴奋的方向是研究如何通过收集人类视频等新的数据收集范例来学习新的技能。
附录G. Example Failure Cases
在图9中,我们提供了语言表设置中一种值得注意的失败类型的示例,其中RT-2模型不能推广到未见过的对象动力学。在这种情况下,尽管该模型能够正确地关注语言指令并移动到第一个正确的对象,但它无法控制这些对象具有挑战性的动力学,这些对象的动力学与在此环境中看到的小型积木对象集(Lynch等人,2022)大不相同。然后,钢笔会从桌子上滚下来(图9左),而香蕉的质心远离机器人接触的位置(图9右)。我们注意到,推动动力学通常很难预测和控制(Yu等人,2016)。我们假设通过进一步扩展包含各种环境和物体的数据集,可能可以在机器人-环境相互作用动力学方面实现更大的泛化——例如,在这种情况下,数据集包括类似类型的各种更复杂的推动力学(Dasari等人,2019)。

此外,尽管在定性和定量的涌现评估中,RT-2 在现实世界操作任务中的表现令人鼓舞,但我们仍然发现了许多值得注意的失败案例。例如,在当前的数据集构成和训练方法下,RT-2 在:
- 通过特定部分(如手柄)抓住物体
- 机器人数据中没有见过的新动作,比如用毛巾擦或使用工具
- 精细的动作,比如叠毛巾
- 需要多层间接推理的扩展推理
其次,虽然我们已经展示了实时运行大型 VLA 模型的能力,但这些模型的计算成本很高。由于这些方法被应用于需要高频控制的环境,实时推理可能会成为主要瓶颈。未来研究的一个令人兴奋的方向是探索量化和蒸馏技术,这可能使这些模型以更高的速率或在更低成本的硬件上运行。这也与另一个当前的局限性有关,即只有少数通用可用的 VLM 模型可用于创建 RT-2。我们希望更多的开源模型能够提供(例如:https://llava-vl.github.io/),私有模型可以开放他们的微调 API,这是构建 VLA 模型的充分要求。
6. Conclusions
在这篇论文中,我们描述了如何通过结合视觉语言模型预训练与机器人数据来训练视觉语言行动 (VLA) 模型。然后,我们基于 PaLM-E 和 PaLI-X 提出了两个 VLA 实现,我们称之为 RT-2-PaLM-E 和 RT-2-PaLI-X。这些模型与机器人轨迹数据共同微调以输出机器人动作,这些动作表示为文本标记。我们展示了我们的方法导致非常高效的机器人策略,并且更重要的是,导致显著更好的泛化性能和从Web 规模的视觉语言预训练继承的能力。我们认为这种简单而通用的方法展示了机器人直接从更好的视觉语言模型中受益的前景,这使机器人学习领域处于一个可以进一步改进的有战略意义的位置,并随着其他领域的进步而改进。